Improving User Research Panels and the Recruitment Process
Stakeholder Interviews • Data Analysis • UX Research Process


Context
As a means of promoting customer-centricity, Mollie created the Insights Community (IC). This is composed of a series of Mollie customers who have agreed to participate in user research initiatives, such as exploratory interviews, surveys, evaluative usability studies, and others. The Insights Community (IC), therefore, allows Mollie to show customers their value in the future of the product(s) that they use and, of course, it allows researchers to recruit participants directly.
However, all information about IC members and their participation status across projects was stored on a simple spreadsheet. Consequently, the process of managing participant recruitment had considerable pain points, such as:
• Manual management process required for updating participation statuses - find the participant, find the project, update the cell, rinse and repeat;
• Not enough information for sound recruitment - the information available was primarily focused on demographics, which by itself could not be enough to know which customers to sample. Any additional information would need to be gathered through other means (e.g., data analysts or back-end engineers);
• Outdated information - even, when the information available was enough to select a sample of customers, this was not always up-to-date.
Consequently, at best, this process was time-consuming, as it often required additional information or confirmation from other stakeholders; however, at worse, this could affect how representative a given sample was, ultimately, affecting the quality of the results.
This page summarises the work that I have done to address these pain points. Admittedly, while this is not a normal research project, such as the others in this portfolio, it is one I had fun with, it had a positive impact in our team's performance, and it shows that you don't always need complex solutions to address a problem.
Team
• 1 Senior User Researcher (yours truly)
My Contributions
• Internal user research (all stages)
• Collect, analyse, and setup data
• Develop complementary widgets
Timeline
• Q1 2022
• ~ 2 weeks (with quick improvements over time)
The Process
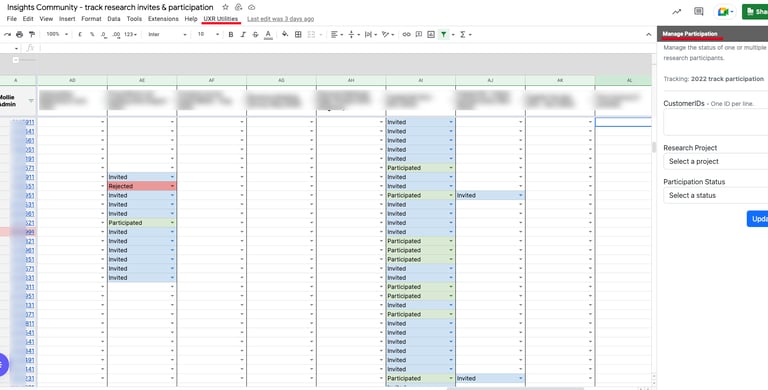
Although transitioning the Insights Community to another platform was not an option, creating a widget was - as such, this was a problem easily solved through engineering. Using Google App Scripts, I created a simple UI where the user (i.e. a Mollie researcher) simply needs to provide the IDs of selected merchants, select the research project they are associated with, and select the participation status required. The widget will then proceed to update all information, in one go.
Solving Pain Point #1: Manual management process
In addition, at a later iteration, easy access and instructions to a custom mass (personalized) emailing feature were added. This as well, was a process that, unless run through another team, would need to be done manually, one invitation at a time (*).
(*) This feature was heavily inspired by this sample, from the Google App Scripts team.
Solving Pain Point #2: Not enough information
While the previous pain point was mostly based on the effort a specific task takes, this one deals with 3 key questions, that define the process followed
(1) What information do we need?
(2) Where can we find that information?
(3) How can we use that information?
Step 1: Identify common information needs for user recruitment and analysis
For this step, interacting with other researchers and product designers was essential.
Through lite interviews and group meetings, we reviewed common recruitment criteria of previous research projects, as well as the most common questions for ongoing and upcoming ones. This allowed me to identify the most common categories of information needed (see step 3).
Step 2: Map information needs to potential data sources
For this step, members of the data and engineering teams were particularly helpful, as they allowed me to find out what information is available, where, and how it is represented.
Ultimately, Looker (integrated with Google Analytics) turned out to be the most complete solution. This tool was already being heavily used by other teams and provided ample access to various types of customer data, where most of which matched our aforementioned information needs, be it directly, or via some data-transformations.
Step 3: Centralise information and setup data for use
Having finally access to the necessary data, I still needed to make it accessible and usable to other stakeholders, without a data analysis -compatible background.
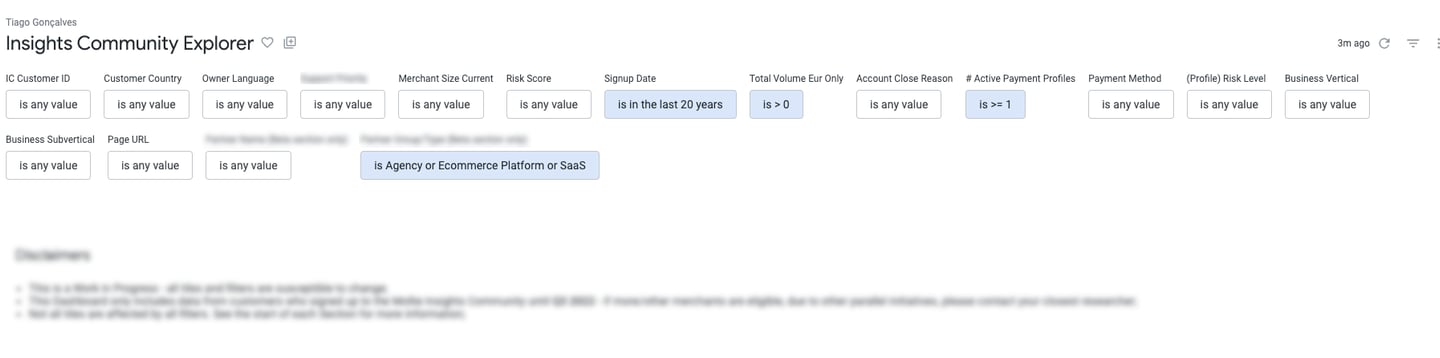
Therefore, I created an exploration dashboard providing the following categories of information, identified in step 1:
• Base Information: general descriptors used to classify the customer, such as demographics (e.g. country, language), or internal support classifications (e.g. compliance risk, customer success metrics);
• Business Classification: including general information about the customer's company, such as their business volume, or their business verticals;
• Platform Usage: including information regarding the types of features that they have active (e.g. payment methods, integrations), or which platforms do they use (i.e. web, mobile);
• Platform Activity: primarily based on Google Analytics data, to understand which pages/features the customers use the most or spend the most time exploring;
• Business Reach: since Mollie is a B2B service, information about the end-consumer of our customers is important as well. This section includes information such as the type of markets that the customers reach to.
Bellow, follow some screenshots of sections of this tool (sensitive information blurred for NDA reasons).
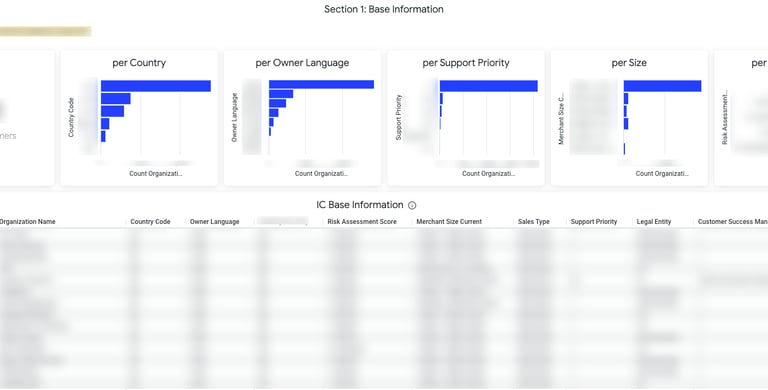

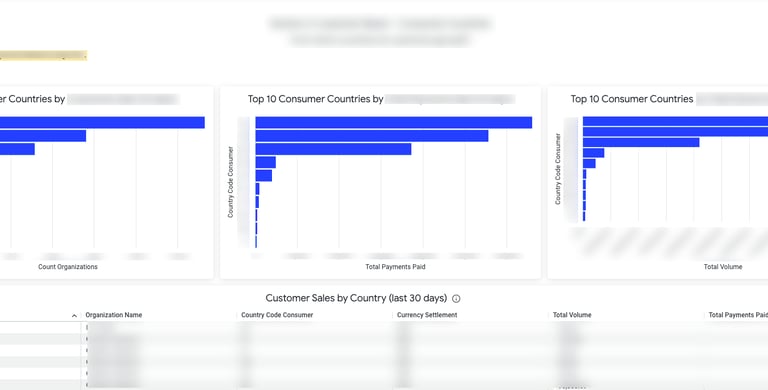
Solving Pain Point #3: Outdated information
The explorer dashboard already helps to address this pain point. However, it was still necessary to have some information available in the aforementioned Insights Community spreadsheet. As such, at a later iteration, an "integration" with Looker was added to this spreadsheet, ensuring that all dynamic information will be consistently updated.
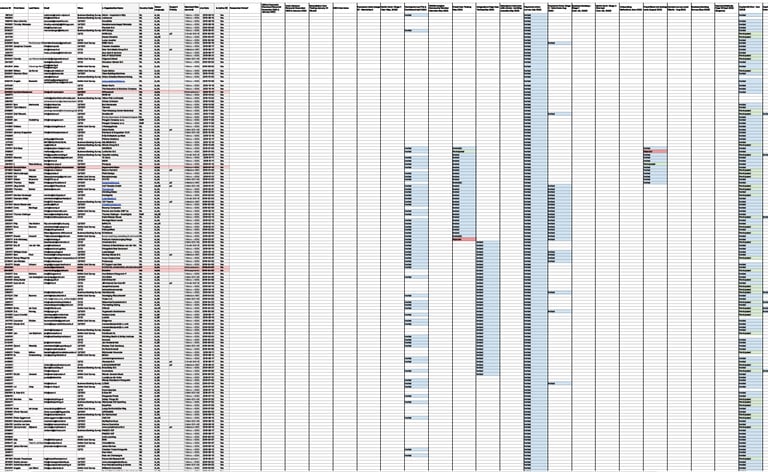

Outcomes
As a result of these optimizations, the following were achieved:
• Less Dependencies: with common useful and/or necessary information readily available, data analysts and engineers do not have to be "bothered";
• Increased Sample Accuracy: as more data dimensions became available, it is now easier to further refine the quality of our sampling - e.g., invite all NL-customers, who registered in the last year, use the mobile app, and have enabled <X payment method>;
• Higher Efficiency: Less time is now spent on repeated manual tasks or waiting for confirmation/information from other stakeholders;
• Improved Communication: as the explorer dashboard is available to any member of the organization, it is now easier to quickly present to stakeholders the profiles of research participants, further bolstering understanding and confidence in the eventual results.